SEO
本节依据谷歌搜索编写,适用于大多数 SEO 场景,对于百度、必应等其他搜索引擎的适配会后续补充
常规指南
保持简单的网址结构
网站的网址结构应尽可能简单些。建议组织一下内容,使网址结构合乎逻辑并易于人们理解。
尽可能在网址中采用易读的字词而非冗长的 ID 编号。
复杂、非描述性的网址:
http://www.example.com/index.php?id_sezione=360&sid=3a5ebc944f41daa6f849f730f1
简单、描述性的网址:
http://en.wikipedia.org/wiki/Aviation
不妨考虑在网址中使用标点符号。这样有助于用户和搜索引擎更轻松地了解网址中的关键字。
将网址中的关键字连接在一起:
http://www.example.com/greendress.html
网址中的关键字用标点符号分隔开:
http://en.wikipedia.org/wiki/Aviation
建议在网址中使用连字符 -,而不要使用下划线 _。
使用下划线 (_):
http://www.example.com/summer_clothing/filter?color_profile=dark_grey
使用连字符 (-):
http://www.example.com/summer-clothing/filter?color-profile=dark-grey
浏览器兼容性
用户通常会使用浏览器访问网站。每个浏览器解析网站代码的方式略有不同,这意味着网站在不同浏览器中显示的效果可能会有所差异。一般情况下,请避免依赖特定于浏览器的行为,例如在未指定内容类型或编码的情况下,希望浏览器可以正确检测到内容类型或编码。此外,还可以采取以下措施,确保网站不会出现意外行为。
在尽可能多的浏览器中测试网站
做好网站设计后,请在多个浏览器中查看网站的外观和功能,确保将独具匠心的设计完美呈现给所有访问者。在理想情况下,建议在网站开发初期就开始测试。各种浏览器(甚至是同一浏览器的不同版本)对同一网站的呈现可能会有所不同。可以使用 Google Analytics(分析)等服务了解访问者最常使用哪些浏览器访问网站。
编写高质量、清晰的 HTML
为了使网页在所有浏览器中显示的效果相同,最好的方法就是使用有效的 HTML 和 CSS 编写网页,然后在尽可能多的浏览器中进行测试。清晰、有效的 HTML 是最保险的方法,而 CSS 可以将网页的外观和内容分离开来,使网页可以更快速地载入和呈现给访问者。可以使用验证工具(例如 W3 Consortium 提供的 HTML)检查网站。
指定字符编码
为了协助浏览器呈现网页上的文字,请为文档指定编码。某些浏览器无法识别文档深处的字符集声明,因此,请将此编码置于文档(或框架)的顶部。此外,请确保网络服务器不会发送相冲突的 HTTP 标头。content-type: text/html; charset=ISO-8859-1 等标头将替换网页中的任何字符集声明。
使网页易于访问
并非所有用户的浏览器都启用了 JavaScript。此外,ActiveX 等技术在某些浏览器中的呈现效果可能并不好(或根本不适用)。建议按照富媒体文件使用指南创建网站,并在 Lynx 等纯文本浏览器中测试网站。如果提供富媒体内容和功能的纯文本替代版本,则有助于搜索引擎更方便地抓取网站并将其编入索引,同时也大大方便了使用屏幕阅读器等其他技术访问网站的用户。
一般性最佳做法
如果确实计划在网站上使用富媒体,请参考以下建议,以免出现问题。
- 尽量只在需要时使用富媒体。 建议使用 HTML 创建内容和导航功能。
- 提供网页的文本版本。 如果首页使用了非 HTML 启动画面,请务必在该首页上添加一个指向文本型网页的常规 HTML 链接,以便用户(或 搜索引擎)无需富媒体也能浏览网站。 一般情况下,搜索引擎会根据文本进行搜索。这意味着内容需采用文本格式,才能被抓取并编入索引。
这并不是说网站中不能包含 Silverlight 或视频等富媒体内容,而是指嵌入这些文件中的任何内容也应通过文本格式提供,否则某些搜索引擎可能无法访问这些内容。以下示例着重介绍最常见类型的非文本内容,但对于其他任何类型的内容,指南要求也同样适用,即需要为所有非文本文件提供对应的文本格式内容。(另外请注意,Flash 不再受支持。)
这不仅会提高搜索引擎抓取内容并将其编入索引的成功率,同时也会使内容更便于访问。很多人(比如有视觉障碍的用户、使用屏幕阅读器的用户或带宽较低的用户)无法看到网页上的图片,因此提供对应的文本内容可以拓宽受众群体。
视频
- 确保所有视频都能在公开网页上访问,用户可以在其中观看视频。确保该网页未被 robots.txt 或
noindex漫游器元标记屏蔽;这样可确保搜索引擎能够找到网页并将其编入索引 - 为了尽可能提高视频曝光率,请为每个视频创建一个专题页,其中视频是该网页上的最突出主题。可以在专题页和原始网页中加入相同的视频以及其他信息,例如商品详情页
- 为视频添加相应的 HTML 标记。如果网页中的视频存在 HTML 标记(例如
<video>、<embed>、<iframe>或<object>),搜索引擎将能更加轻松地识别该视频
如果网站嵌入了来自第三方平台的视频,搜索引擎可能会将网页及第三方托管网站中对等网页上的视频同时编入索引。这两个版本可能都会出现在搜索引擎的视频功能中。
iframe
iframe 有时用于在网页上显示内容。通过 iframe 显示的内容可能不会被编入索引,也可能不会在搜索结果中显示。因此,建议避免使用 iframe 显示内容。如果网站中使用了 iframe,请务必额外提供指向 iframe 所显示内容的文本型链接,以便搜索引擎能够抓取这些内容并将其编入索引。
Flash
Flash 不再受支持。
避免创建重复内容
重复内容通常是指网域内或网域间与其他内容完全匹配或大致类似的有一定体量的内容。多数情况下,其成因并不具有欺骗性质。非恶意重复内容可包括:
- 既可生成常规网页,又可针对移动设备生成精简版网页的论坛
- 通过多个不同网址显示或链接的商店项目
- 网页的打印专用版本
可采取一些措施来主动解决内容重复的问题并确保访问者可看到希望他们看到的内容。
- 使用 301 重定向:如果已调整了网站结构,那么请使用 301 重定向(“RedirectPermanent”)来灵活地重定向用户、Googlebot 和其他“蜘蛛”程序。
- 保持一致:尽量使内部链接保持一致。例如,请勿链接到
http://www.example.com/page/``、http://www.example.com/page和http://www.example.com/page/index.htm。 - 使用顶级域名:为便于搜索引擎选用最恰当的文档版本,请尽量使用顶级域名来处理针对特定国家/地区的内容。例如,与
http://www.example.com/cn或http://cn.example.com相比,http://www.example.cn更能说明这是专为中国提供的内容。 - 联合供稿须谨慎:如果以联合供稿方式在其他网站上显示内容,那么,在每次相关搜索中,Google 都会始终显示搜索引擎认为最适合用户的版本,这有可能是首选版本,也有可能不是。不过,建议确保以联合供稿形式展示相应内容的每个网站都包含一个指回原始文章的链接。也可要求其他网站的站长对包含联合供稿资料的网页使用 noindex 元标记,从而阻止搜索引擎将那些版本编入索引。
- 最大限度地减少重复的样板文字:例如,不在每个网页的底部添加冗长的版权文字,而只添加一段简短摘要,然后链接到能够提供详细信息的网页。此外,还可以使用参数处理工具指定希望 Google 处理网址参数的方式。
- 避免发布无实际内容的网页:用户不喜欢看到“空白”网页,因此请尽量避免使用占位内容。例如,请勿发布尚无实际内容的网页。如果确实需要创建占位符网页,请使用 noindex 元标记阻止搜索引擎将这些网页编入索引。
- 了解自己的内容管理系统:请务必熟悉内容在网站上的显示方式。博客、论坛以及相关系统往往会以不同的格式显示相同的内容。例如,某个博客条目可能会显示在博客首页、存档网页以及包含带有同一标签的其他条目的网页中。
- 最大限度地减少相似内容:如果多个网页内容相似,那么,请考虑扩充每个网页的内容,或将这些网页合并成一个。例如,如果网站上包含与两个城市分别对应的不同网页,但这两个网页中的内容相同,便可将这两个网页合并为一个网页来同时介绍这两个城市的相关信息,或者扩充每个网页的内容以使其包含相应城市的独特信息。
不建议使用 robots.txt 文件或其他方法阻止抓取工具访问网站上的重复内容。如果搜索引擎无法抓取包含重复内容的网页,便无法自动检测这些网址是否指向相同内容,导致误将它们视为独立的不同网页。一个更好的解决方案是允许搜索引擎抓取这些网址,并使用 rel="canonical" link 元素、网址参数处理工具或 301 重定向将这些网址标记为重复内容。
确保链接可供抓取
只有当链接使用正确的 <a> 标签和可解析的网址时,搜索引擎才能跟踪这些链接。
使用正确的 <a> 标记
只有链接是含有 href 属性的 <a> 标记时,搜索引擎才能跟踪这些链接。搜索引擎的抓取工具不会跟踪使用其他格式的链接。搜索引擎无法跟踪缺少 href 标记的 <a> 链接,也无法跟踪含有其他通过脚本事件起到链接作用的标记的 <a> 链接。以下是搜索引擎可以跟踪以及无法跟踪的链接示例:
可以跟踪的链接示例:
<a href="https://example.com">
<a href="/relative/path/file">
<a routerLink="some/path">
<span href="https://example.com">
<a onclick="goto('https://example.com')">
指向可解析网址的链接
确保 <a> 标记所链接到的网址是搜索引擎可以向其发送请求的实际网址,例如:
https://example.com/stuff
/products
/products.php?id=123
javascript:goTo('products')
javascript:window.location.href='/products'
确保搜索引擎未被阻止
阻止搜索引擎访问某个网站会直接影响搜索引擎抓取该网站的内容并将其编入索引,还可能导致该网站搜索结果中的排名下降。搜索引擎需要访问网站才能检索并遵守其 robots.txt 文件中的指令。
抓取和索引编制
站点地图 - sitemap.xml
robots.txt
robots.txt 文件规定了搜索引擎抓取工具可以访问网站上的哪些网址。此文件主要用于避免网站收到过多请求;它并不是一种阻止搜索引擎抓取某个网页的机制。若想阻止搜索引擎访问某个网页,请使用 noindex 禁止将其编入索引,或使用密码保护该网页。
robots.txt 对不同文件类型的影响
| 文件类型 | 影响 |
|---|---|
| 网页 | 对于网页(包括 HTML、PDF),可在以下情况下使用 robots.txt 文件管理抓取流量:认为来自 Google 抓取工具的请求会导致服务器超负荷;或者,不想让 Google 抓取网站上的不重要网页或相似网页。 警告 如果不想让自己的网页显示在 Google 搜索结果中,请不要将 robots.txt 文件用作隐藏网页的方法。 如果其他网页通过使用说明性文字指向网页,Google 在不访问网页的情况下仍能将其网址编入索引。如果想从搜索结果中屏蔽自己的网页,请改用其他方法,例如使用密码保护或 noindex。 如果使用 robots.txt 文件阻止 Google 抓取网页,则其网址仍可能会显示在搜索结果中,但搜索结果不会包含对该网页的说明。 而且,图片文件、视频文件、PDF 文件和其他非 HTML 文件都会被排除在外。如果看到了这样一条与网页对应的搜索结果并想修正它,请移除屏蔽该网页的 robots.txt 条目。 |
| 媒体文件 | 可以使用 robots.txt 文件管理抓取流量并阻止图片、视频和音频文件出现在 Google 搜索结果中。这不会阻止其他网页或用户链接到图片/视频/音频文件。 |
| 资源文件 | 如果认为在加载网页时跳过诸如不重要的图片、脚本或样式文件之类的资源不会对网页造成太大影响,可以使用 robots.txt 文件屏蔽此类资源。不过,如果缺少此类资源会导致 Google 抓取工具更难解读网页,请勿屏蔽此类资源,否则 Google 将无法有效分析有赖于此类资源的网页。 |
robots.txt 限制
- 并非所有搜索引擎都支持 robots.txt 指令。 robots.txt 文件中的命令并不能强制规范抓取工具对网站采取的行为;是否遵循这些命令由抓取工具自行决定。Googlebot 和其他正规的网页抓取工具都会遵循 robots.txt 文件中的命令,但其他抓取工具未必如此。因此,如果想确保特定信息不会被网页抓取工具抓取,我们建议采用其他屏蔽方法,例如用密码保护服务器上的隐私文件。
- 不同的抓取工具会以不同的方式解析语法。 虽然正规的网页抓取工具会遵循 robots.txt 文件中的指令,但每种抓取工具可能会以不同的方式解析这些指令。需要好好了解一下适用于不同网页抓取工具的正确语法,因为有些抓取工具可能会无法理解某些命令。 如果其他网站上有链接指向被 robots.txt 文件屏蔽的网页,则此网页仍可能会被编入索引
- 尽管 Google 不会抓取被 robots.txt 文件屏蔽的内容或将其编入索引。 但如果网络上的其他位置有链接指向被禁止访问的网址,我们仍可能会找到该网址并将其编入索引。因此,相关网址和其他公开显示的信息(如相关页面链接中的定位文字)仍可能会出现在 Google 搜索结果中。若要正确阻止网址出现在 Google 搜索结果中,应为服务器上的文件设置密码保护、使用 noindex 元标记或响应标头,或者彻底移除网页。
meta 标签
常用的 meta 标签
| meta 标签 | 作用 |
|---|---|
<meta name="description" content="A description of the page"> | 此标签用于提供一段有关网页的简短说明。在某些情况下,此说明将用在搜索结果中显示的摘要中 |
<meta charset="utf-8"> | 此标签会定义网页的内容类型和字符集。请确保已在内容属性值的两端添加了引号,否则系统可能会错误地解译字符集属性。尽可能使用 Unicode/UTF-8 |
<meta name="viewport" content="width=device-width, initial-scale=1.0"> | 此标签可告知浏览器如何在移动设备上呈现网页。该标签的存在可向搜索引擎表明该网页适合移动设备 |
使用 noindex 阻止搜索引擎编入索引
可以通过在 HTTP 响应中包含 noindex 元标记,阻止网页或其他资源显示在 Google 搜索中。当 Googlebot 下次抓取该网页并发现该标记或标头时,就会完全阻止该网页出现在 Google 搜索结果中,不论是否有其他网站链接到该网页。
<meta name="robots" content="noindex">
整合重复网址
规范网址:Google 认为在网站的一组重复网页中最具代表性的网页的网址。举例来说,如果同一个网页有多个网址(example.com?dress=1234 和 example.com/dresses/1234),Google 便会从中选择一个网址作为规范网址。 网页不必完全相同;列表页面在排序或过滤方面的细微变化并不会使该页面具有唯一性(例如,按价格排序或按项目颜色过滤)。
规范网址所在的网域可以与相应重复网址的网域不同。
有很多合理原因可能会导致网站上有多个不同的网址指向同一个网页,或者内容重复或非常相似的网页位于不同的网址。以下是最常见的原因:
- 为了支持多种设备类型
- 为了启用搜索参数或会话 ID 等所需的动态网址
- 当同一篇博文同时放在多个版块中时,博客系统会自动保存多个网址
- 服务器已配置为针对 www/非 www、http/https 变体提供相同的内容
- 相应博客上提供的要转载到其他网站上的内容与这些网域中的原有内容完全重复或部分重复
从一组重复网页/类似网页中明确选择规范网页的原因有很多:
- 指定希望用户在搜索结果中看到的网址。可能希望用户通过 https://www.example.com/dresses/green/greendress.html(而非 https://example.com/dresses/cocktail?gclid=ABCD)访问绿色礼服商品页。
- 整合类似网页或重复网页的链接信号。明确选择规范网页可帮助搜索引擎将它们掌握的关于各个网址的信息(例如,指向它们的链接)整合到一个首选网址上。也就是说,从其他网站指向 http://example.com/dresses/cocktail?gclid=ABCD 的链接会与指向 https://www.example.com/dresses/green/greendress.html 的链接整合。
- 简化单个商品/主题的跟踪指标。如果特定内容可以通过多个网址访问,获取此内容的综合指标的难度会更大。
- 管理转载内容。如果是为了将内容发布到其他网域而对其进行转载,那么需要确保首选网址会出现在搜索结果中。
- 避免花费时间抓取重复网页。希望 Googlebot 在网站上发现尽量多的内容,因此最好让 Googlebot 将时间用于抓取网站上的新网页(或更新后的网页),而不是抓取相同网页的桌面版和移动版。
常规指南
无论使用哪种规范化方法,都请遵循以下常规指南:
- 请勿使用 robots.txt 文件进行规范化。
- 请勿使用网址移除工具进行规范化,它会从搜索结果中移除网址的所有版本。
- 请勿使用相同或不同的规范化方法为同一网页指定不同的规范网址(例如,请勿既在站点地图中为某个网页指定一个规范网址,又使用
rel="canonical"为同一网页另行指定一个规范网址)。 - 请勿使用
noindex阻止选择规范网页。此指令旨在从索引中排除网页,而不是管理对规范网页的选择。 - 使用 hreflang 标记时,请务必指定规范网页。指定一个采用同一语言的规范网页;如果没有这样的规范网页,则指定一个采用最佳替代语言的规范网页。
- 在网站中提供链接时,请务必链接到规范网址(而非重复网址)。始终链接到认定的规范网址有助于 Google 了解偏好的网址。
优先选择 HTTPS(而非 HTTP)网址作为规范网址
Google 会优先选择 HTTPS 网页(而非等效的 HTTP 网页)作为规范网页。
虽然搜索引擎在默认情况下会优先选择 HTTPS 网页(而非 HTTP 网页),但可以通过执行以下任一操作来确保此行为始终都会发生:
- 添加从 HTTP 网页指向 HTTPS 网页的重定向。
- 添加从 HTTP 网页指向 HTTPS 网页的
rel="canonical"link。 - 实施 HSTS。
为防止 Google 误将 HTTP 网页选为规范网页,请避免以下几种做法:
- 避免使用错误的 TLS/SSL 证书和 HTTPS 到 HTTP 重定向,因为这会导致搜索引擎非常倾向于选择 HTTP 网页。即使实施 HSTS 也无法消除这种强烈的倾向。
- 避免在站点地图或 hreflang 条目中包含 HTTP 网页(而不是 HTTPS 版本)。
- 避免为错误的主机版本实施 SSL/TLS 证书。例如,在 example.com 上提供 www.example.com 的证书。此证书必须与完整网站网址匹配,或者必须是可用于同一网域上多个子网域的通配证书。
使用 rel="canonical" link 标记
可以在 HTML 的 head 部分使用 <link> 标记,指明某个网页与另一个网页重复的情况。
假设将 https://example.com/dresses/green-dresses 设为规范网址(即使有很多个网址指向该内容),那么可通过执行以下步骤,将此网址指定为规范网址:
- 使用
rel="canonical"link 元素标记所有重复网页。
将具有 rel="canonical" 属性的 <link> 元素添加到重复网页的 <head> 部分中,并使其指向规范网页。例如:
<link rel="canonical" href="https://example.com/dresses/green-dresses" />
- 如果规范网页有移动版,请为其添加
rel="alternate"link,并使该链接指向此网页的移动版:
<link rel="alternate" media="only screen and (max-width: 640px)" href="http://m.example.com/dresses/green-dresses">
- 为此网页添加适当的 hreflang 或其他重定向。
对于 rel="canonical" link 标记,请使用绝对路径(而非相对路径)。
- 👍 建议: https://www.example.com/dresses/green/greendresss.html
- 👎 不建议: /dresses/green/greendress.html
使用 rel="canonical" HTTP 标头
配置服务器,可使用 rel="canonical" HTTP 标头(而不是 HTML 标记)为 Google 搜索支持的文档(包括 PDF 文件等非 HTML 文档)指明规范网址。
目前,Google 仅支持在网页搜索结果中使用此方法。
如果通过多个网址显示某个 PDF 文件,可以返回 rel="canonical" HTTP 标头,将该 PDF 文件的规范网址告知 Googlebot:
Link: <http://www.example.com/downloads/white-paper.pdf>; rel="canonical"
关于 rel="canonical" HTTP 标头的建议与 rel="canonical" link 标记相同。根据 RFC2616 的规定,只能在 rel="canonical" HTTP 标头中使用英文双引号。
使用站点地图
请分别为每个网页选择一个规范网址,然后通过站点地图提交这些规范网址。在站点地图中列出的所有网页都会被视为向系统建议的规范网页;Googlebot 会根据内容相似度决定哪些网页是重复网页(如果有)。
搜索引擎不能保证一定会将站点地图中的网址视为规范网址,但可通过这种简单的方法为大型网站指定规范网址,也可以通过站点地图这种实用方法告知 Google 认为自己网站上的哪些网页最重要。
请勿在站点地图中添加非规范网页。如果使用站点地图,请仅在站点地图中指定规范网址。
对已停用的网址使用 301 重定向
如果想移除现有的重复网页,但需要确保在停用旧网址之前顺利完成迁移,请使用此方法。
假定用户可通过以下几种方式访问网页:
可从这些网址中挑选一个作为规范网址,并使用 301 重定向将来自其他网址的流量引导至首选网址。服务器端 301 重定向是确保将用户和搜索引擎定向到正确网页的最佳方式。301 状态代码表示网页已永久地迁移到新位置。
网站迁移和变更
重定向
重定向网址是将现有网址解析为不同网址的做法,相当于告知访问者和 Google 搜索某个网页有新的地址。重定向在以下情况下尤为有用:
- 已将网站移至新网域,并且想尽可能顺畅地完成迁移。
- 用户可通过多个不同的网址访问网站。例如,如果用户可通过多种途径(如 http://example.com/home、http://home.example.com 或 http://www.example.com)访问首页,那么最好选择其中一个网址作为首选(规范)目标网址,并使用重定向将所有来自其他几个网址的流量转到该首选网址。
- 正在合并两个网站,并且想确保指向旧网址的链接重定向至正确网页。
- 移除了某个网页,并希望将用户转到新网页。
重定向类型概览
- 永久重定向:在搜索结果中显示新的重定向目标。
- 临时重定向:在搜索结果中显示源网页。
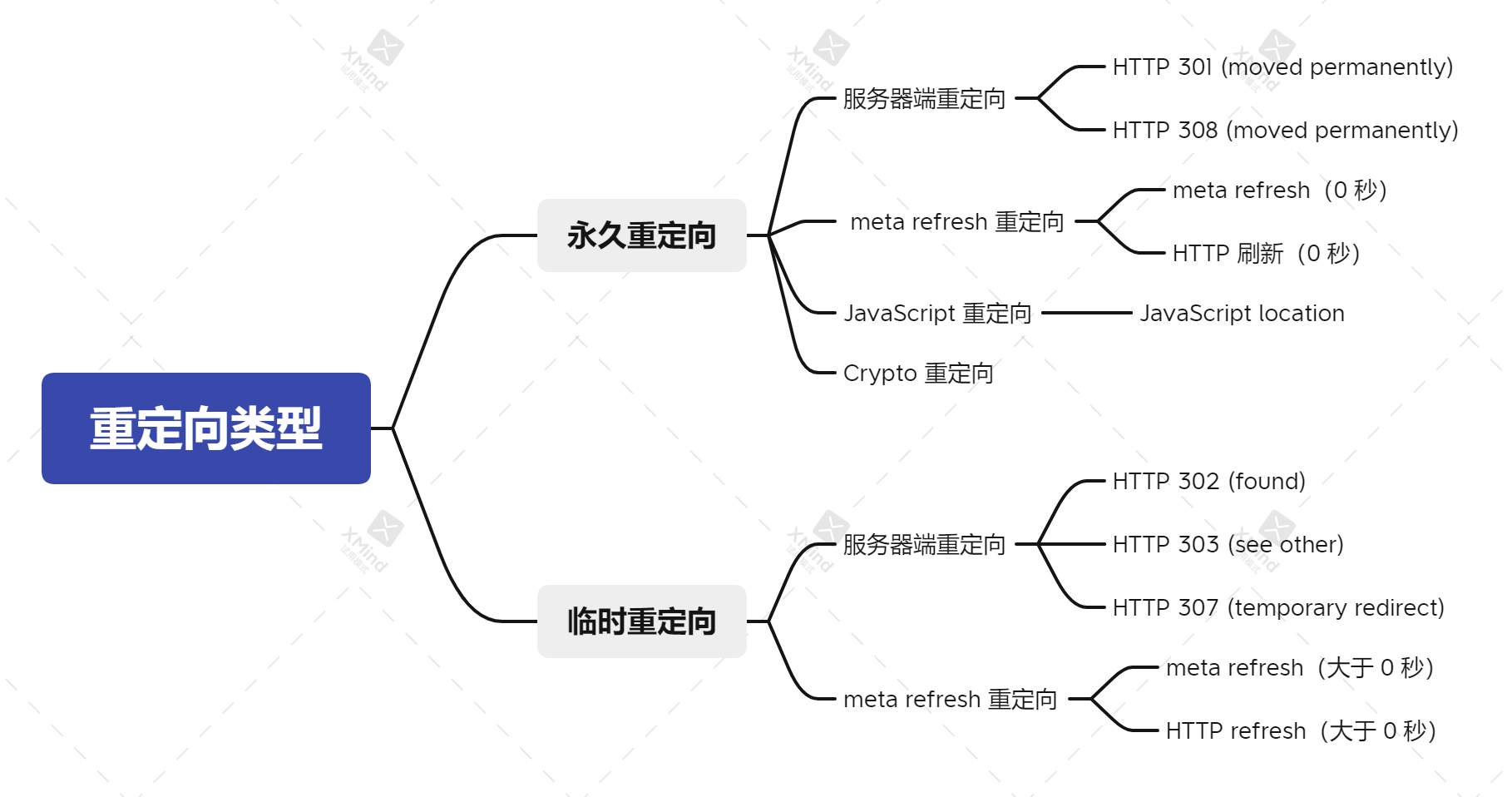
服务器端重定向
- 永久服务器端重定向
如果需要更改某个网页在搜索引擎结果中显示的网址,建议尽可能使用永久服务器端重定向。这是确保将 Google 搜索和用户定向到正确网页的最佳方式。301 和 308 状态代码表示网页已永久地迁移到新位置。
- 临时服务器端重定向
如果只是想暂时将用户转到其他网页,请使用临时重定向。这样还可以确保 Google 将旧网址在搜索结果中保留更长时间。例如,如果网站提供的某项服务暂时不可用,可以设置临时重定向,将用户转到说明情况的网页,而不会影响搜索结果中的原始网址。
meta refresh 及其 HTTP 等效项
如果无法在平台上实施服务器端重定向,那么 meta refresh 重定向或许是一种可行的替代方案。Google 会区分两种 meta refresh 重定向:
- 即时 meta refresh 重定向:在浏览器加载网页时立即触发。Google 搜索会将即时 meta refresh 重定向解析为永久重定向。
- 延迟 meta refresh 重定向:仅在网站所有者设置的任意秒数之后触发。Google 搜索会将延迟 meta refresh 重定向解析为临时重定向。
JavaScript location 重定向
仅在无法实施服务器端重定向或 meta refresh 重定向时,才使用 JavaScript 重定向。虽然 Google 会尝试呈现 Googlebot 抓取到的每个网址,但可能会由于各种原因而呈现失败。这意味着,如果设置了 JavaScript 重定向,但 Google 无法呈现相应内容,那么 Google 可能永远都无法看到该重定向。
Crypto 重定向
如果无法采用任何传统的重定向方法,仍应设法告知用户相应网页或其内容已迁移。实现此目的的最简单的方法是添加指向新网页的链接并随附简短说明。例如:
<a href="https://newsite.example.com/newpage.html">We moved! Find the content on our new site!</a>
请勿依赖 Crypto 重定向来告知搜索引擎内容已迁移,除非别无选择。
网站迁移
将自己的网站迁移到其他网址或基础架构,称为网站迁移。
在不更改网址的情况下迁移网站
复制和测试新网站
可以通过全面测试用户与网站的互动方式来验证网站是否可以正常运行。以下是几点建议:
- 在网络浏览器中打开新网站,然后检查网站的所有元素:网页、图片、表单及下载内容(例如 PDF 文件)。
- 创建测试环境(例如按照 IP 限制访问权限),从而在网站上线前测试其所有功能。
- 可以为新基础架构设置一个临时主机名(如 beta.example.com)来进行公开测试,以便测试通过浏览器访问网站的可访问性。借助临时主机名,可以测试 Googlebot 能否访问网站。
- 如果可以的话,可以使用少量的实时流量测试新网站。
降低 DNS 记录的 TTL 值
若要提高网站迁移速度,可以降低网站 DNS 记录的 TTL 值,从而更快地将新设置迁移至 ISP。DNS 设置通常由 ISP 基于指定的存留时间 (TTL) 设置进行缓存。请考虑在网站迁移前至少提前一周将 TTL 设置为保守的低值(例如,几个小时),以加快 DNS 缓存的刷新速度。
开始网站迁移
迁移过程如下所述:
- 移除所有会被抓取的临时数据块。在创建网站的新副本时,有些网站所有者会使用 robots.txt 文件禁止 Googlebot 和其他抓取工具的所有抓取活动,或者使用 noindex 元标记或 HTTP 标头阻止将内容编入索引。在准备开始迁移时,请务必从网站的新副本中移除所有此类数据块。
- 更新 DNS 设置。由于 DNS 缓存设置已被缓存,记录需要一些时间才能完全传播到互联网上的所有用户。
在更改网址的情况下迁移网站
以下是一些此类网站迁移的示例:
- 协议更改:如将网址从 HTTP 更改为 HTTPS
- 域名更改:如将
example.com更改为example.net - 网址路径更改:如将
example.com/page.php?id=1更改为example.com/widget
为新网站设置 robots.txt 文件
网站的 robots.txt 文件能够控制 Googlebot 可抓取的范围。请确保新网站的 robots.txt 文件中的指令正确反映了想要禁止抓取的部分。
请注意,某些网站所有者会在开发期间禁止抓取任何内容。如果采取这种策略,请务必准备好在网站迁移开始时要使用的 robots.txt 文件。同样,如果在开发期间使用 noindex 指令,请准备好开始网站迁移时需从中移除 noindex 指令的网址列表。
针对已删除或已合并的内容提供错误消息
对于不会被转移到新网站的旧网站内容,请确保这些孤立网址能够正确返回 HTTP 404 或 410 错误响应代码。可以在新网站的配置面板中进行设定,让这些旧网址返回错误响应代码,或者为新网址创建重定向并使其返回 HTTP 错误代码。
请不要将多个旧网址重定向至一个无关的目标,如新网站的首页。这样做可能会令用户感到困惑,并可能会被视为软 404 错误。但是,如果将之前在多个网页上托管的内容合并成了一个新网页,可将多个旧网址重定向至这个合并后的新网页。
准备网址映射
- 确定当前网址
在最简单的网站迁移情形中,可能并不需要生成当前网址列表。例如,如果要更改网站的域名(例如从 example.com 更改为 example.net),那么可以使用通配符服务器端重定向。
在更为复杂的网站迁移中,需要生成旧网址列表,并将其映射到相应的新目标网址。
- 创建从旧网址到新网址的映射
获取旧网址列表后,即可决定每个网址应该重定向至哪个目标网址。存储此映射的方式取决于服务器及网站迁移。对于常见的重定向模式,可以使用数据库或在系统上配置一些网址重写规则。
- 更新所有网址详情
定义网址映射后,需要完成三项工作,为迁移做好网页准备。
-
针对每个网页更新 HTML 或站点地图条目中的注解
- 每个目标网址都应该有一个自引用
rel="canonical" <link>标记。 - 如果迁移的网站包含多语言或多地区版本且使用了
rel-alternate-hreflang注解的网页,请务必更新这些注解,以便使用新网址。 - 如果迁移的网站有对应的移动版本,请务必更新
rel-alternate-media注解。
- 每个目标网址都应该有一个自引用
-
更新内部链接。将新网站上的内部链接从旧网址更改为新网址。可以根据需要使用之前生成的映射帮助查找和更新链接。
-
创建并保存站点地图及链接列表。保存以下列表,以便进行最终的网站迁移:
- 包含映射中新网址的站点地图文件
- 包含映射中旧网址的站点地图文件
- 链接到当前内容的网站列表
-
为 301 重定向做好准备
在定义好映射且新网站准备就绪后,下一步就是在服务器上依据指示的映射关系,设置从旧网址到新网址的 HTTP 301 重定向。
请注意以下几点:
- 使用 HTTP 301 重定向。虽然 Googlebot 支持多种重定向,但搜索引擎建议尽量使用 HTTP 301 重定向。
- 避免使用重定向链。虽然 Googlebot 和各个浏览器能够追踪由多个重定向组成的“链”(例如,网页 1 > 网页 2 > 网页 3),但搜索引擎建议直接重定向至最终目标网址。如果无法做到这一点,请尽量减少重定向链中的重定向次数,最好是不超过 3 次,且要尽量小于 5 次。重定向链会增加用户的等待时间,而且并非所有浏览器都支持较长的重定向链。
开始网站迁移
待网址映射已准确创建且重定向已正常运行后,就可以开始迁移网站了。
- 确定如何迁移网站 - 是一次性迁移,还是按版块迁移:
- 中小型网站:搜索引擎建议同时迁移网站上的所有网址,而不是一次仅迁移一个版块。这既有助于用户与新形式的网站更好地互动,也有助于搜索引擎的算法更快速地检测到网站迁移并更新索引。
- 大型网站:可以选择一次迁移一个版块。这样更便于监控和检测问题,以及更快速地修正问题。
- 更新 robots.txt 文件:
- 在旧网站上,移除所有 robots.txt 指令。 此操作会使 Googlebot 发现所有指向新网站的重定向并更新搜索引擎的索引。
- 在新网站上,确保 robots.txt 文件允许所有抓取操作。这包括抓取图片、CSS、JavaScript 和其他网页资源,确定不想抓取的网址除外。
- 配置旧网站,以便根据网址映射将用户和 Googlebot 重定向至新网站。
- 尽可能长时间保留重定向,通常保留至少 1 年。 在此期间,Google 会将所有信号都转移给新网址,包括重新抓取和重新分配其他网站上指向旧网址的链接。
从用户的角度来看,不妨考虑无限期地保留重定向。但是,重定向对于用户来说速度较慢,因此请尽力将自己的链接和所有来自其他网站的高流量链接更新为指向新网址。
Googlebot 及搜索引擎的系统需要花费一段时间才能发现并处理网站迁移中的所有网址,所需的具体时间将取决于服务器的速度和所涉网址的数量。一般来说,中型网站可能需要几周的时间才能迁移大多数网页,大型网站则可能需要更长的时间。Googlebot 和搜索引擎的系统发现及处理已迁移网址的速度取决于网址数量和服务器速度。
请注意,在迁移过程中,内容在搜索结果中的曝光率可能会暂时出现波动。这种情况很正常,过一段时间网站排名便会稳定下来。
暂停或停用网站
如果无法履行订单或许多商品缺货,可能会考虑暂时关闭在线商家。如果这种情况是暂时的,也就是说预计在未来几个星期或几个月内就能够销售商品,搜索引擎建议采取措施,尽量使网站在 Google 搜索中的排名保持不变。
限制网站的功能(推荐做法)
如果上述情况是暂时的,也打算让在线商家重新开张,搜索引擎建议让网站保持在线状态,并限制网站功能。搜索引擎之所以推荐这种方法,是因为它能够尽量避免网站在 Google 搜索中的显示情况受到负面影响。用户仍然可以找到商品、查看评价或添加心愿单,以便日后购买商品。搜索引擎建议采取以下做法:
- 停用购物车功能:停用购物车功能是最简单的方法,并且不会对网站在 Google 搜索中的显示情况产生任何影响。
- 显示横幅或弹出式窗口:通过在所有网页(包括着陆页)中显示横幅或弹出式窗口 div,能够快速地向用户说明相关状况。说明所有已知和异常的延迟、送货时间、取货或送货方式,这样用户就不会在后续操作中抱有过高的预期。 为了防止横幅或弹出式窗口中的内容显示在 Google 搜索结果摘要中,请使用
data-nosnippetHTML 属性。
停用整个网站(不推荐)
Google 系统采用了可靠的设计,可以帮助网站从暂时性问题中恢复正常。不过,从 Google 索引中彻底移除网站是一项重大变更,需要相当长的一段时间才能恢复。彻底移除后的恢复过程所需的时间是不固定的,也没有加速完成此过程的机制。因此,搜索引擎强烈建议限制网站功能,而不要从 Google 搜索中移除网站。
可以决定停用整个网站。这种极端措施应该限制在极短的时间内(最多执行几天时间),否则即使在正确实施的情况下,也会在 Google 搜索中对网站产生重大影响。
如果确定要执行此操作(重申下,搜索引擎不推荐这种做法),可以采用以下方案:
- 如果需要将网站紧急停用 1-2 天,应该返回包含 503 HTTP 结果代码(而不是所有内容)的信息性错误页面。请务必遵循关于停用网站的最佳做法。
- 如果需要将网站停用更长时间,应该使用 200 HTTP 状态代码提供一个可编入索引的首页作为占位符,供用户在 Google 搜索中查找。
关于停用网站的最佳做法
请注意,如果网页返回了 503 HTTP 结果代码,则 Google 系统无法刷新网站中包含的标题、说明、元数据或结构化数据。
虽然搜索引擎不建议停用网站,但如果决定执行此操作,请遵循以下最佳做法:
- 👍 通过 robots.txt 文件继续允许抓取。不要针对 robots.txt 文件返回 503 HTTP 结果代码,因为这样做会屏蔽所有抓取。
- 👍 使用 curl 或类似工具在本地确认 503 HTTP 结果代码。例如:
curl -I -X GET "https://www.example.com/"
HTTP/1.1 503 Service Unavailable
Mime-Version: 1.0
Content-Type: text/html
(...)
- 👍 为了尽量降低 503 错误页面的服务器端和客户端负载,请遵循以下最佳做法:
- 使用 Retry-After HTTP 标头 注明会争取在哪一天恢复或问题可能会持续多长时间。
- 使用静态 HTML。
- 尽量减少页外资源;使用内嵌 CSS 样式表和 base-64 编码图片。
- 👍 在错误页面的内容中向用户提供关于后续步骤的明确指南。其中可以包括:
- 指向详细信息的链接
- 预计网站恢复在线状态的日期或信息的更新日期
- 如何与客户服务人员联系
- 👎 不要在 robots.txt 文件中禁止所有抓取操作。如果返回禁止所有抓取操作的有效 robots.txt 文件,网站的内容(甚至其网址)可能会从 Google 搜索中移除。
- 👎 不要通过返回 403、404、410 HTTP 状态代码,或者使用
noindex漫游器元标记或 x-robots-tag HTTP 标头屏蔽网站。这样做会从 Google 搜索中移除网站的网址。 - 👎 不要使用 503 HTTP 结果代码屏蔽 robots.txt 文件。
软 404 错误
软 404 是一个网址,会在返回的页面中向用户表明目标网页不存在,同时还会返回 200 OK 状态代码。在某些情况下,软 404 可能会是一个内容很少或不含任何内容的页面(例如,一个只含零星内容的页面或空页面)。
返回成功状态代码而不是 404 Not Found、410 Gone 或 301 Permanent Redirect 是一种不好的做法。成功状态代码等于告知搜索引擎,通过该网址可以找到实际的网页。因此,该网页可能会列在搜索结果中,搜索引擎将继续尝试抓取这个不存在的网址,而不是将时间用于抓取实际网页。
网页和内容已不再存在
如果移除了相应网页,并且网站上没有含类似内容的替换网页,请针对该网页返回 404 Not Found 或 410 Gone 响应(状态)代码。这些状态代码会告知搜索引擎:该网页不存在,相应内容不应编入索引。
如果有权访问服务器的配置文件,可以自定义这类错误页面(自定义 404 页面),以便为用户提供帮助。一个好的自定义 404 页面会帮助用户找到所需信息,还会提供其他实用内容,促使用户进一步浏览网站。以下是一些技巧,帮助设计实用的自定义 404 页面:
- 明确告诉访问者无法找到其要找的网页。采用友好并有吸引力的语言。
- 确保 404 页面的外观和风格(包括导航方式)与网站的其他网页一致。
- 考虑添加指向以下内容的链接:最热门文章/博文以及网站首页。
- 不妨提供一种供用户报告链接损坏的方式。
网页或内容现已移到别处
如果网页已移走或有明确的替换网页,请返回 301 Permanent Redirect 以重定向用户。这样做不会中断用户的浏览体验,还是一种将网页新位置告知搜索引擎的好办法。
网页和内容仍然存在
如果系统将某个本身正常的网页标记为软 404 错误,可能是因为 Googlebot 无法正常加载该网页,或是因为它在呈现期间缺少重要资源。如果呈现的是空白或几乎空白的网页,可能是因为该网页引用了许多无法加载的资源(图片、脚本和其他非文本元素),这种情况可能会被解读为软 404 错误。无法加载资源的原因包括:资源被屏蔽(遭到 robots.txt 屏蔽)、网页包含的资源过多/过大,或者资源加载速度缓慢。
国际性和多语言网站
JavaScript 内容
Googlebot 对 JavaScript 网络应用的处理流程分为 3 大阶段:
- 抓取
- 呈现
- 编入索引
Googlebot 会抓取并呈现网页,然后将其编入索引。
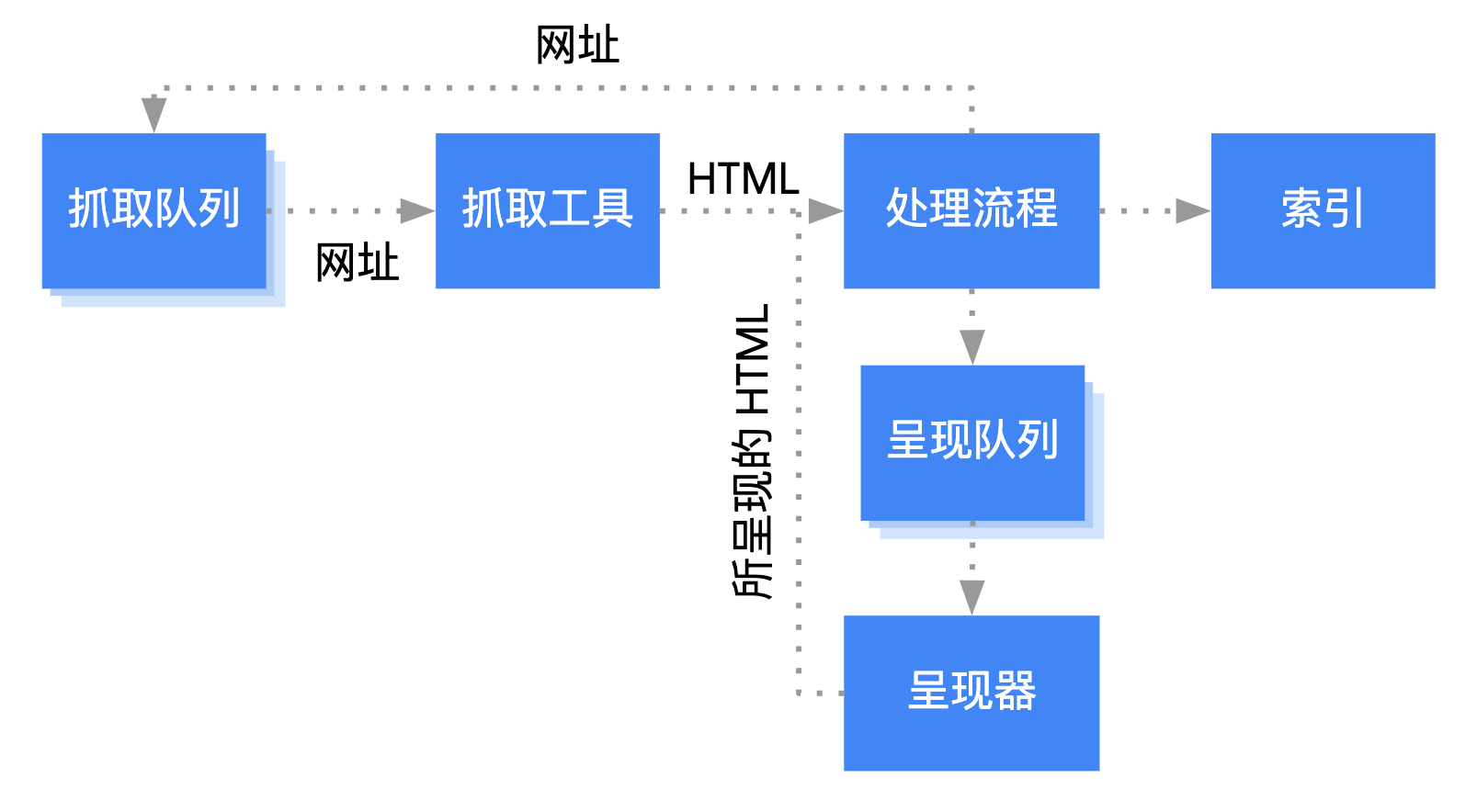
当 Googlebot 尝试通过发出 HTTP 请求从抓取队列中抓取某个网址时,它首先会检查是否允许抓取。Googlebot 会读取 robots.txt 文件。如果此文件将该网址标记为“disallowed”,Googlebot 就会跳过向该网址发出 HTTP 请求的操作,然后会跳过该网址。
接下来,Googlebot 会解析 HTML 链接的 href 属性中其他网址的响应,并将这些网址添加到抓取队列中。若不想让 Googlebot 发现链接,请使用 nofollow 机制。
抓取网址并解析 HTML 响应非常适用于经典网站或服务器端呈现的网页(在这些网站或网页中,HTTP 响应中的 HTML 包含所有内容)。某些 JavaScript 网站可能会使用应用 Shell 模型(在该模型中,初始 HTML 不包含实际内容,并且 Googlebot 需要执行 JavaScript,然后才能查看 JavaScript 生成的实际网页内容)。
Googlebot 会将所有网页都加入呈现队列,除非漫游器元标记或标头告知 Googlebot 不要将网页编入索引。网页在此队列中的存在时长可能会是几秒钟,但也可能会是更长时间。一旦 Googlebot 的资源允许,无头 Chromium 便会呈现相应网页并执行 JavaScript。Googlebot 会再次解析所呈现的链接 HTML,并将找到的网址加入抓取队列。Googlebot 还会使用所呈现的 HTML 将网页编入索引。
请注意,依然建议采取服务器端呈现或预呈现,因为:
- 它可让用户和抓取工具更快速地看到网站内容;
- 并非所有漫游器都能运行 JavaScript。
目前除了谷歌之外,其他搜索引起对 JavaScript 的支持不友好。对于需要 SEO 的项目,建议使用 Nuxt.js 而非 Vue。Nuxt.js 支持服务端渲染(SSR),可以生成 HTML 代码供搜索引擎抓取。
用独特的标题和摘要描述网页
独特的描述性 <title> 元素和有用的元描述可帮助用户快速找到符合其目标的最佳结果。搜索引擎的指南中解释了怎样才算是良好的 <title> 元素和元描述。
可以使用 JavaScript 设置或更改元描述及 <title> 元素。
编写兼容的代码
浏览器提供了很多 API,而 JavaScript 是一种快速演变的语言。Googlebot 对所支持的 API 和 JavaScript 功能有一些限制。如果使用功能检测机制检测到所需的某个浏览器 API 缺失了,谷歌建议使用差异化呈现和 polyfill。
使用有意义的 HTTP 状态代码
Googlebot 会通过 HTTP 状态代码确定抓取网页时是否出现了问题。
如需告知 Googlebot 无法抓取某个网页或无法将某个网页编入索引,请使用有意义的状态代码(例如:404 表示找不到网页,401 代码表示必须登录才能访问网页)。可以使用 HTTP 状态代码告知 Googlebot 某个网页是否已移至新网址,以便系统相应地更新索引。
避免单页应用中出现软 404 错误
在客户端呈现的单页应用中,路由通常实现为客户端路由。 在这种情况下,使用有意义的 HTTP 状态代码可能是无法实现或不实际的。 为避免在使用客户端呈现和路由时出现软 404 错误,请采用以下策略之一:
- 使用 JavaScript 重定向至服务器响应 HTTP 404 状态代码(例如
/404)的网址。 - 使用 JavaScript 向错误页面添加
<meta name="robots" content="noindex">。
以下是重定向方法的示例代码:
fetch(`/api/products/${productId}`)
.then(response => response.json())
.then(product => {
if(product.exists) {
showProductDetails(product); // shows the product information on the page
} else {
// this product does not exist, so this is an error page.
window.location.href = '/404'; // redirect to 404 page on the server.
}
})
以下是 noindex 标记方法的示例代码:
fetch(`/api/products/${productId}`)
.then((response) => response.json())
.then((product) => {
if(product.exists) {
showProductDetails(product); // shows the product information on the page
} else {
// this product does not exist, so this is an error page.
// Note: This example assumes there is no other meta robots tag present in the HTML.
const metaRobots = document.createElement('meta');
metaRobots.name = 'robots';
metaRobots.content = 'noindex';
document.head.appendChild(metaRobots);
}
})
使用 History API 而非 Hash
Googlebot 在网页中查找链接时,只考虑 href HTML 链接属性中的网址。
对于实现客户端路由的单页应用,请使用 History API在 Web 应用的不同视图之间实现路由。为确保 Googlebot 能够找到链接,请避免使用 Hash 加载不同的网页内容。
慎重地使用漫游器元标记
可以通过漫游器元标记阻止 Googlebot 将某个网页编入索引或跟踪链接。 例如,在网页顶部添加以下元标记可阻止 Googlebot 将该网页编入索引:
<!-- Googlebot won't index this page or follow links on this page -->
<meta name="robots" content="noindex, nofollow">
可以使用 JavaScript 将漫游器元标记添加到网页中或更改其内容。以下示例代码展示了如何使用 JavaScript 更改漫游器元标记以防止在 API 调用未返回内容时将当前网页编入索引。
fetch(`/api/products/${productId}`)
.then((response) => response.json())
.then((apiResponse) => {
if (apiResponse.isError) {
// get the robots meta tag
let metaRobots = document.querySelector('meta[name="robots"]');
// if there was no robots meta tag, add one
if (!metaRobots) {
metaRobots = document.createElement('meta');
metaRobots.setAttribute('name', 'robots');
document.head.appendChild(metaRobots);
}
// tell Googlebot to exclude this page from the index
metaRobots.setAttribute('content', 'noindex');
// display an error message to the user
errorMsg.textContent = 'This product is no longer available';
return;
}
// display product information
// ...
});
Googlebot 在运行 JavaScript 之前,如果在漫游器元标记中遇到 noindex,便不会呈现相应网页,也不会将其编入索引。
如果 Googlebot 遇到 noindex 标记,就会跳过呈现和 JavaScript 执行步骤。 由于 Googlebot 会在这种情况下跳过 JavaScript,因此没有机会从网页上移除标记。 使用 JavaScript 更改或移除漫游器元标记可能会行不通。如果漫游器元标记最初包含 noindex,Googlebot 会跳过呈现和 JavaScript 执行步骤。 如果确实希望将网页编入索引,请勿在原始网页代码中使用 noindex 标记。
搜索结果呈现
<title>
<title> 元素可告诉用户和搜索引擎特定网页的主题是什么。请将 <title> 元素放在 HTML 文档的 <head> 元素中,并为网站上的每个网页创建独一无二的标题文字。
关于编写描述性 <title> 元素的最佳做法
标题链接非常重要,它可以让用户快速了解某条搜索结果的内容以及该结果与其查询相关的原因。它常常是用户在决定点击哪个结果时参考的主要信息,因此为网页提供高品质的标题文字非常重要。
- 确保在
<title>元素中为网站上的每个网页分别指定一个标题。 - 为
<title>元素编写简练的描述性文字。避免使用不明确的描述,例如对首页使用“首页”,或对某人的个人资料使用“个人资料”。还要避免<title>元素中出现无谓地冗长/罗嗦的文字,因为这种文字显示在搜索结果中时可能会被截断。 - 避免关键字堆砌。在
<title>元素中包含几个描述性词汇有时会有帮助,但请勿多次重复使用相同的字词或短语。“Foobar, foo bar, foobars, foo bars”这样的标题文字对用户并没有帮助,而且此类关键字堆砌可能会导致 Google 和用户将结果视为垃圾内容。 - 避免
<title>元素中出现重复或样板化的文字。网站上每一个网页的<title>元素中都应该有独特的描述性文字。例如,将商业网站每个网页的标题都写成“出售便宜商品”就会导致用户无法区分两个网页。如果<title>元素中的标题很长并且只有一小部分有变化(“样板”标题),那么也不合适;例如,所有网页的共用<title>元素中包含“乐队名称 - 查看视频、歌词、海报、专辑、评价和音乐会”这样的文字,这种标题就包含大量没有参考价值的文字。- 一种解决方法是动态更新
<title>元素,以更好地体现网页的实际内容。例如,只有在特定网页包含视频或歌词时才使用“视频”、“歌词”等词。另一种方法是仅使用乐队的实际名称作为<title>元素中的简要文字,同时使用元描述说明网页的内容。
- 一种解决方法是动态更新
- 简明扼要地在标题中宣传品牌。网站首页的
<title>元素中可以包含一些有关网站的额外信息,例如:
<title>ExampleSocialSite, a place for people to meet and mingle</title>
但是,如果在网站的每个网页的 <title> 元素中都显示该文字,就会在系统针对同一查询返回网站的多个网页时显得重复和罗嗦。在这种情况下,不妨考虑仅在每个 <title> 元素的开头或末尾添加网站名称,并用连字符、冒号或竖线等分隔符将其与文字的其余部分隔开,如下所示:
<title>ExampleSocialSite: Sign up for a new account.</title>
- 请注意关于禁止搜索引擎抓取网页的问题。在网站上使用 robots.txt 协议可以阻止 Google 抓取网页,但不一定能阻止网页被编入索引。例如,如果 Google 通过其他网站上的链接发现了网页,可能就会将网页编入索引。如果搜索引擎无法访问网页上的内容,就会依赖页外内容生成标题链接,例如来自其他网站的定位文字。可以使用 noindex 指令禁止 Google 将某个网址编入索引。
避免出现常见的 <title> 元素问题
下面列出了网页上的 <title> 元素最常出现的问题。
如果搜索引擎检测到网页的
<title>元素存在问题,搜索引擎可能会尝试根据定位文字、网页中的文字或其他信息生成经过改进的标题链接。
| 常见问题 | 描述 |
|---|---|
<title> 元素不完整 | 缺少部分标题文字。例如: Google 搜索会查看标头元素中的信息或网页上的其他大型醒目文字来生成标题链接: |
<title> 元素已过时 | 如果网站年复一年地使用同一个网页呈现周期性信息,但没有更新 在此示例中,该网页包含一个内容为“2021 年录取标准”的大型醒目资讯标题,但 |
<title> 元素不准确 | 当 Google 搜索会尝试确定 |
<meta name="description">
创建优质元描述的最佳做法
Google 有时会利用网页中的 <meta name="description"> 标记生成搜索结果摘要,因为在这些情况下,Google 认为与完全来自网页内容的摘要相比,这样生成的摘要可以为用户提供更准确的描述。元描述标记通常用简短且相关的摘要告知用户特定网页的内容是什么,并引起用户的兴趣。它们应当像宣传标语一样,旨在让用户确信相应网页正是他们要找的网页。元描述没有长度限制,但 Google 搜索结果中的摘要会在必要时被截断,通常是为了适应设备宽度。
- 确保网站上的每个网页都有元描述。
- 为网站上的每个网页创建独特的描述。如果网站上的每个网页都使用相同或相似的描述,当多个网页同时出现在搜索结果中时,这些描述并不会起到很大的帮助。因此,请尽量创建能够准确概括特定网页的描述。可以在首页或其他汇总页上使用网站级描述,在所有其他网页上使用网页级描述。如果没有时间为每个网页分别创建描述,请尝试为内容划分优先级;至少为关键网址(例如,首页和热门网页)创建一个描述。
- 在描述中添加内容相关信息。元描述并非必须为句子格式,也可以包含关于网页的信息。例如,新闻或博文可以列出作者、发布日期或署名信息。这可为潜在访问者提供相关度非常高的信息,如果没有这些数据,摘要中就不会显示这些信息。同样,产品页也可能包含一些分散在网页各处的重要信息片段,如价格、生产日期、制造商等。良好的元描述可将所有这些数据汇总在一起。例如,下列元描述提供了有关某书籍的详细信息。
<meta name="description" content="Written by A.N. Author,
Illustrated by V. Gogh, Price: $17.99,
Length: 784 pages">
在本例中,每项信息都被清楚地标记并分隔开来。
- 程序化地生成描述。对于某些网站(例如新闻媒体来源),为每个网页生成准确且独特的描述非常简单:由于每篇文章都是手写的,因此再添加一句描述也毫不费力。对于较大型的由数据库驱动的网站,例如商品汇总网站,手写描述是无法完成的。不过,在后一种情况下,程序化地生成描述较为可行,建议不妨一试。良好的描述应当简单易懂,并且不能千篇一律。网页级数据就非常适合以程序化方式生成。请注意,包含很多长串关键字的元描述不会让用户清楚地了解网页内容,也不太可能代替常规摘要显示出来。
- 使用高质量的描述。最后,确保描述确实具有描述性。由于元描述不会显示在用户看到的网页中,因此此类内容很容易被忽视。不过,高质量的描述会显示在 Google 的搜索结果中,并会对搜索流量的质量和数量产生长远的促进作用。
定义要在搜索结果中显示的网站图标
如果网站有网站图标,则它可以显示在与网站对应的 Google 搜索结果中。
<link rel="icon" href="favicon.ico">
网站图标的网址。该网址可以是相对路径 (/favicon.ico),也可以是绝对路径 (https://example.com/favicon.ico),但必须与首页处于同一网域中。
必须遵循以下指南,才能使网站图标显示在搜索结果旁边。
- 一个网站只能设置一个网站图标,而网站由主机名定义。例如,
https://www.example.com/和https://code.example.com/是两个不同的网站,因此可以设置两个不同的网站图标。但是,https://www.example.com/sub-site是网站的子目录,只能为https://www.example.com/设置一个网站图标,该图标适用于相应网站及其子目录。 - 网站图标文件和首页都必须可供 Google 抓取(也就是说,不能阻止 Google 访问它们)。
- 为便于用户在浏览搜索结果时快速识别网站,请确保网站图标的视觉设计能够代表网站品牌。
- 网站图标必须为正方形,且其边长应是 48px 的倍数,例如 48x48px、96x96px、144x144px 等。SVG 文件没有具体尺寸限制。系统支持任何有效的网站图标格式。Google 会将图片重新调整为 16x16px,这样才能在搜索结果中使用,因此请确保该图片在此分辨率下有良好的视觉效果。
注意:请勿提供 16x16px 的网站图标。
- 网站图标网址必须保持稳定(请勿经常更改该网址)。
即使遵循了所有这些指南,搜索引擎也不能保证网站图标一定会显示在搜索结果中。